On This Page
2021.12-2022.6 **(Research)** Improvement and Realization of Stochastic Contextual Bandit Problem
On This Page
- Graduation Thesis Project, supervised by Dr. Zhengyang Liu
Main Work
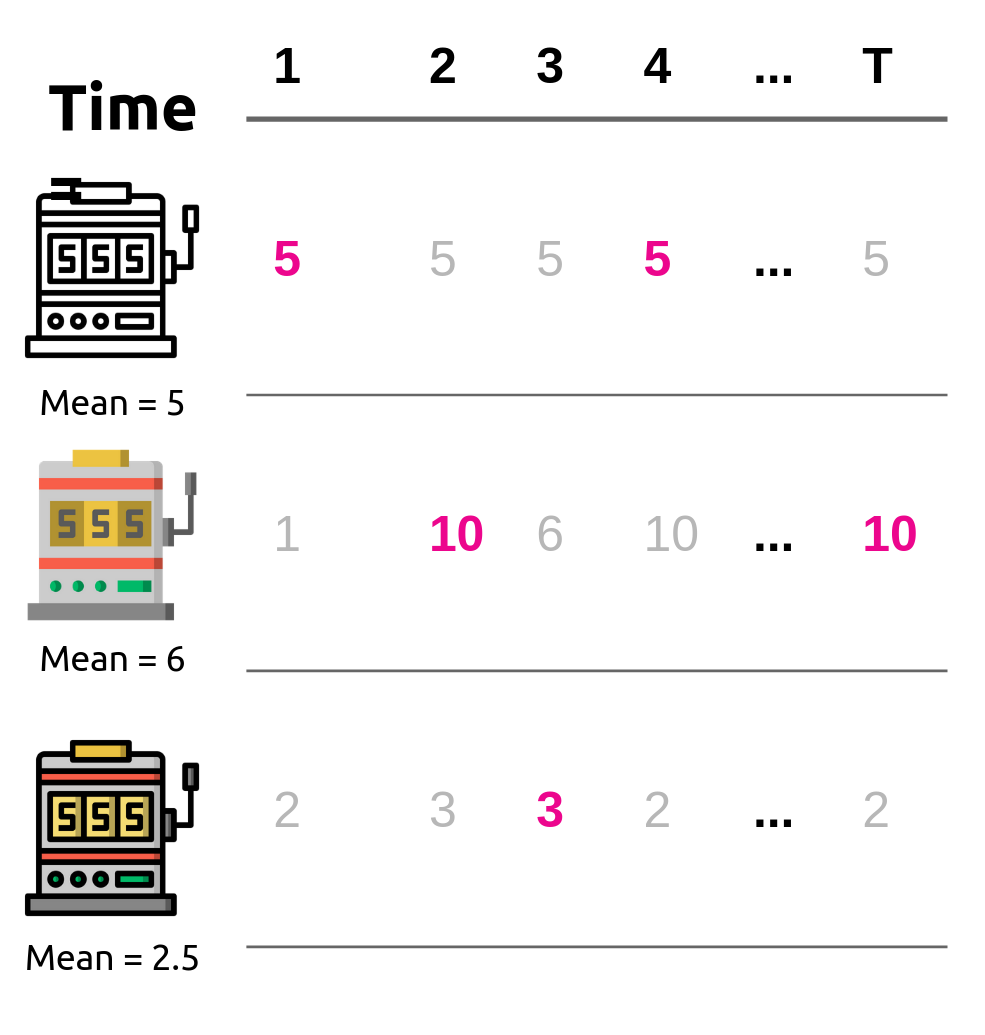
- Focused on the stochastic contextual bandit problem, the NeuralUCB algorithm improves the ε-Greedy Algorithm by utilizing upper confidence bound (UCB) based exploration to optimize stochastic multi-armed bandit.
- Proposed a novel model with a Long Short Term Memory (LSTM) network to extract temporal data of the reward function.
- Experimented on the synthetic datasets to verify how agent selected action and compared the ETC, UCB, and ε-Greedy using the accumulated regret and the ratio of selecting optimal action as the performance metric in the stochastic multi-armed bandit problem.
- Compared the LinUCB, NeuralEpsilonGreedy, LstmUCB and NeuralUCB using the accumulated reward and ratio of selecting optimal action in the stabilization stage based on the synthetic dataset of the nonlinear reward function.
- Experimental results showed that LstmUCB Algorithm outperformed the NeuralUCB algorithm in periodic reward function, and NeuralEpsilonGreedy-based exploration outperformed NeuralUCB on certain datasets, thus verifying the validity of the proposed improvement method.
Bandit Problem (Pic from Internet)
Tech Stack
- Theory
- Bandit Theory(ε-greedy & UCB)
- Reinforcement Learning
- Programming
- Python
- Pytorch